Code reuse is alleged to be one of the prime benefits of object-oriented programming. Rather than solving a problem from scratch, you simply derive a subclass[1] from an existing class and override a few methods. The reality is considerably less promising than the theory. Although design patterns describe object-oriented designs, they are based on practical solutions that have been implemented in mainstream object-oriented programming languages like Java and C++ rather than procedural languages like (C, Fortran 77, and Cobol). This site chose Java and C++ for pragmatic reasons: Our day-to-day experience has been in these languages, and they are increasingly popular. The choice of programming language is important because it influences one's point of view. Our patterns assume Java and C++ level language features, and that choice determines what can and cannot be implemented easily. If we assumed procedural languages, we might have included design patterns called "Inheritance," "Encapsulation," and "Polymorphism. But since these OO-Design Principles are already part of the Java language, these elements are not classified as patterns.
Challenges in Designing Reusable Classes in C++
In the sphere of software engineering, particularly within the domain of C++, designing reusable classes is a coveted objective. Reusability fosters efficiency, consistency, and maintainability. However, achieving this in the intricate landscape of C++ is not without its challenges. The following is a comprehensive examination of the main obstacles that developers confront when designing reusable classes in C++:
Complexity of Inheritance:
Deep Inheritance Hierarchies: While inheritance promotes code reuse, a deeply nested hierarchy can lead to a loss of clarity and increased maintenance challenges.
Multiple Inheritance: C++ supports multiple inheritance, but it can introduce ambiguities, especially when two base classes have member functions with identical signatures.
Template Challenges:
Compilation Errors: C++ templates, though powerful, can produce verbose and convoluted compilation errors, making them difficult to debug.
Code Bloat: Overuse or inappropriate use of templates can lead to code duplication in the compiled binary, increasing its size.
Memory Management:
Ownership Ambiguities: In a reusable class, it can be challenging to determine who owns an object and is responsible for its deallocation, leading to memory leaks or double deletions.
Shallow vs. Deep Copy: Creating reusable classes requires careful consideration of copying semantics. Mismanagement can lead to unintentional sharing or excessive copying of data.
Lack of Reflection and Introspection:
C++ lacks native reflection capabilities. This absence makes it challenging to design classes that can adapt based on their properties or behaviors, limiting some aspects of reusability.
Platform-Dependent Behavior:
Ensuring consistent behavior across different platforms and compilers can be daunting. Features like bitfields, endianness, and even some undefined behaviors in C++ can affect the portability of reusable classes.
Decoupling and Dependency Management:
A reusable class should be as decoupled as possible. However, ensuring minimal dependencies while maintaining functionality can be challenging, especially when integrating with legacy code.
Versioning and Backward Compatibility:
Over time, as the class evolves, maintaining backward compatibility becomes crucial for reusability. Ensuring new versions of a class do not break existing applications is a persistent challenge.
Balancing Flexibility and Simplicity:
Designing a class to be universally applicable can make its interface and implementation complex. Striking a balance where a class is both reusable and straightforward is a nuanced endeavr.
Thread Safety:
With the rise of multi-threaded applications, ensuring that reusable classes are thread-safe is paramount. However, integrating thread safety mechanisms can introduce performance overhead and complexity.
Standardization and Documentation:
For a class to be reusable, developers outside its original project should be able to understand and employ it. Comprehensive documentation, clear naming conventions, and adherence to coding standards are essential, yet often overlooked or inconsistently applied.
In conclusion, while the ethos of C++ offers a fertile ground for the development of reusable classes, the path is laden with intricate challenges. Mastery in designing such classes demands not only a deep understanding of the language but also a foresighted approach that anticipates potential pitfalls and navigates the delicate balance between generality and specificity.
The fact is, designing classes is hard, and designing reusable classes is even harder. The best estimates reveal that even experienced object-oriented programmers take three times as long to design a class that can be reused in other contexts as they do to solve the immediate problem they face.
Given this time cost, it is no wonder that few programmers explicitly code for reuse. Software projects are routinely understaffed, under-budgeted and over deadline. Although a class you actually reuse can repay its cost of development on the fourth project, few organizations have the human capital needed to invest in truly reusable code. In fact, reuse is often considered only by companies developing class libraries for third party use, where the extra cost of designing for reuse can be repaid hundreds of times over on many thousands of different projects.
Object-oriented Design
When designing a system for an object- oriented implementation, you must:
Identify the participants in the system: The participants in the system can be thought of as the actors participating in a use case.
Factor them into classes at the right level of granularity
Define the public interface of each class:
Establish inheritance hierarchies
Define the relationships between classes
Experienced developers may be able to build a working solution through this procedure. However it is almost unheard of for even experienced designers to build a reusable solution on their first attempt. Before you can build an extensible, reusable system, you are probably going to have to build a prototype to find out where your errors and misconceptions are.
The purpose of the prototype is get the basic functionality off the ground and to see if your "proof of concept" can be enhanced using future iterations. Once you understand design patterns and have had a mind altering experience with them, you will not ever think about object-oriented design in the same way. You will have insights that can make your own designs more flexible, modular, and reusable, which is why you're interested in object-oriented technology in the first place.
Abstract Data Types, Interfaces, and Pre- and Postconditions
One of the goals of object-oriented programming is to write reusable code, which is code that can be reused in many different applications, preferably without having to be recompiled. One way to make code reusable is to encapsulate a group of data elements representing an object together with its operations (functions and operators) in a separate program module (a class). A new program can use the functions to manipulate the data without being concerned about details of the data representation and the implementation of its operations. In this way, the class can be used as a building block to construct new application programs. The combination of data together with its operations is called an (ADT) abstract data type .
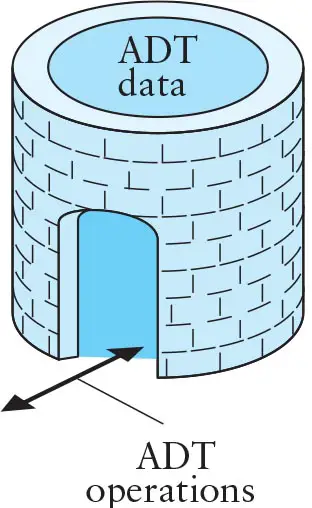
Figure 2.2 shows a diagram of an abstract data type[2]. The data values stored in the ADT are hidden inside the circular wall. The bricks around this wall are used to indicate that these data values cannot be accessed except by going through the ADT's operations. A class provides one way to implement an ADT in C++. If the data fields are private, they can be accessed only through public functions. Therefore, the functions control access to the data and determine the manner in which the data is manipulated. A primary goal of this course is to show you how to write and use ADTs in programming. As you progress through this course, you will create a large collection of ADT implementations (classes) in your own program library.
Because each ADT implementation in your library will already have been coded, debugged, and tested, using them would make it much easier for you to design and implement new application programs. In addition, the C++ Standard Library provides a rich collection of ADT implementations. You will be introduced to many of the ADTs and design patterns as you progress through this course.
Figure 2.2 Diagram of an ADT
[1]subclass: A class that is derived from a particular class, perhaps with one or more classes in between.
[2]abstract data type: In programming, an abstract data type, is data type defined by its behavior, rather than its implementation.